최근에 자료구조와 함께 배우는 알고리즘 입문(자바편) 책을보고 예전에 대학교 시절에 대충 배웠던 자료구조에 대해서 자세하게 공부할 기회가 생겨서 리뷰를 하게 되었습니다.
확실히 책은 한번 읽는것보다 여러번 읽어보니 그때는 왜 이런걸 못봤을까…하는 생각이 듭니다.
스택과 큐에 대해서 간단하게 코드 리뷰와 이러한 자료구조를 어디에서 사용되는지도 다시 한번 알게된 계기가 되었습니다.
스택(Stack)
스택은 데이터를 일시적으로 저장하기 위해 사용하는 자료구조로, 선입선출(가장 나중에 넣은 데이터를 가장 먼저 꺼내는) 방식입니다. 음… 이걸 읽고 생각나는게… 아침에 출근을 할때 지하철을 타게되면 분명 가장먼저 탔는데 내릴때는 가장 늦게내리는 제 모습이 생각나는군요…묘하게 비슷합니다.
스택의 구조
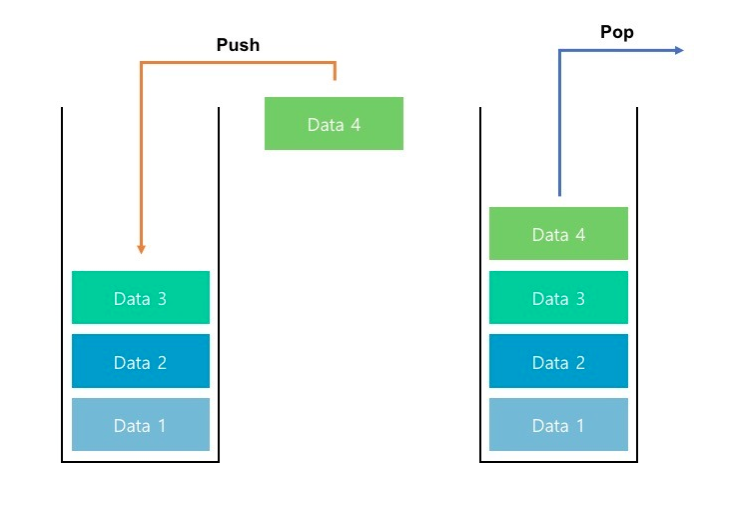
맨 처음에 스택이라는 배열에는 Data 1, Data 2, Data 3이 들어왔고, 그 다음으로 Data 4가 들어왔습니다. 이때 스택안으로 자료를 넣는 작업을 Push라고 합니다. 그리고 해당 데이터를 꺼내는 작업을 Pop이라고 합니다. 이때 알아두어야 할 점은 내가 원하는 데이터를 꺼낼수 있는게 아니라 스택에서 가장 후입(늦게 들어온 데이터)된 데이터를 꺼낸다는 점입니다.
스택은 사용자가 구현한 Java 프로그램에서 메서드를 호출하고 실행할 때 프로그램 내부에서는 스택을 사용합니다. 다음 아래와 같이 main메서드를 포함한 총 4개의 메서드로 이루어진 코드로 스택을 살펴보겠습니다.
스택 사용의 예제
void x(){
System.out.println("x를 호출하였습니다.")
}
void y(){
System.out.println("y를 호출하였습니다.")
}
void z(){
x();
y();
System.out.println("z를 호출하였습니다.")
}
int main(){
z();
}먼저 사용자가 작성한 자바소스 코드는 javac 컴파일러라는 녀석에 의해서 기계어로 번역되고 만약 문법적인 오류가 없다면 해당 소스코드를 class 파일로 만든 후 클래스 로더라는 녀석이 JVM이 관리하고 있는 각각의 메모리 영역에 로딩을 하게 됩니다. 그리고 JVM은 프로그램 흐름이 시작하는 main 메서드를 찾게됩니다.
위의 코드에서 main 메서드를 가장 먼저 찾아서 스택에 Push를 수행합니다. main 메서드는 스코프 안에 정의되어 있는 z 메서드를 호출합니다. 마찬가지로 z메서드에서 x 메서드를 호출하게 됩니다.
그러면 스택에서 main -> z -> x 순으로 Push가 수행되고 x 메서드가 실행종료 되면 다시 z 메서드로 돌아오는데 이때 스택에서는 x 메서드를 Pop하는 작업을 수행하게 됩니다.
z 메서드는 y 메서드를 호출하고, 스택에서는 Push를 수행하여 main -> z -> y 순으로 쌓여 있습니다. y 메서드가 실행종료되면, 다시 z 메서드로 돌아오고 더 이상 실행할 문장이 없이 종료가 되면 스택 영역에서 Pop 작업이 수행됩니다. 그러면 스택 안에서는 더 이상 main 메서드 밖에 남지 않게 됩니다. main 메서드도 실행할 문장이 존재하지 않다면 스택에서 Pop이 이루어지고 프로그램이 종료가 됩니다.
이처럼 스택은 가장 나중에 저장된 데이터가 가장 먼저 인출되는 방식으로 동작합니다.
아래 소스코드는 스택에서 사용할 수 있는 메소드를 책을보고 구현해본 코드입니다.
public class IntStack {
int max; //스택 용량 총 배열의 크기를 말함
int ptr; //스택에 쌓여있는 데이터 수를 나타낸다.
int[] stk; //스택 본체를 의미한다.
//실행 시 예외: 스택이 비어 있을때
public class EmptyIntStackException extends RuntimeException {
public EmptyIntStackException() {
}
}
//실행 시 예외: 스택이 가득 차 있을때
public class OverflowIntStackException extends RuntimeException {
public OverflowIntStackException() {
}
}
//생성자를 통해서 IntStack 클래스의 맴버변수들을 초기화 수행
public IntStack(int capacity) {
this.ptr = 0;
this.max = capacity;
try {
this.stk = new int[max];
} catch (OutOfMemoryError e) {
max = 0;
}
}
//스택영역에 데이터를 Push를 수행하는 메서드
public int push(int x) throws OverflowIntStackException {
if (ptr >= max) //데이터의 개수가 스택 용량과 크거나 같으면 오버플로우 예외 발생
throw new OverflowIntStackException();
return stk[ptr++] = x;
}
//스택영역에 데이터를 Pop을 수행하는 메서드
public int pop() throws EmptyIntStackException {
if (ptr <= 0) //데이터의 개수가 0보다 작거나 같으면 EmptyIntStack 예외 발생
throw new EmptyIntStackException();
return stk[--ptr];
}
//peek은 엿보다라는 뜻으로 스택영역에서 가장 늦게 들어온 데이터를 읽어서 출력하는 메서드
public int peek() throws EmptyIntStackException {
if (ptr <= 0) { //마찬가지로 스택이 비어있으면 EmptyIntStack 예외 발생
throw new EmptyIntStackException();
}
return stk[ptr - 1];
}
//특정 데이터의 index를 가져오는 메서드
public int indexOf(int x) {
for (int i = ptr - 1; i >= 0; i--)
if (stk[i] == x)
return i;
return -1; //해당 데이터가 존재하지 않으면 -1을 리턴
}
//스택에 있는 데이터를 비우는 메서드
public void clear() {
ptr = 0;
}
//스택의 용량을 확인하는 메서드
public int capacity() {
return max;
}
//스택의 데이터 개수를 확인하는 메서드
public int size() {
return ptr;
}
//dump 메서드는 가장 먼저 들어온 데이터부터 숱차적으로 읽어서 출력하는 메서드
public void dump() {
if (ptr <= 0)
System.out.println("스택이 비어 있습니다.");
else {
for (int i = 0; i < ptr; i++)
System.out.print(stk[i] + " ");
System.out.println();
}
}
}큐(Queue)
마지막으로 살펴볼 큐는 스택과 마찬가지로 데이터를 일시적으로 쌓아 놓은 자료구조입니다. 하지만 가장 구별되는 특징은 가장 먼저 넣은 데이터를 가장 먼저 꺼내는 선입선출인 점이 스택과 다릅니다.
예를들어서 대형마트 같은곳에서 계산을 할때에는 대기열 맨앞에 줄을서는 고객이 먼져 계산하고 나가는게 대표적이네요. 어떻게보면 공정하다고 할 수 있는 자료구조라고 생각됩니다…
큐의 구조

큐에 데이터를 넣는 작업을 인큐(enqueue)라 하고, 데이터를 꺼내는 작업을 디큐(dequeue)라고 합니다.
또 데이터를 꺼내는 쪽을 프런트(front)라 하고, 데이터를 넣는 쪽을 리어(rear)라고 합니다.
위의 그림에서 보듯이 큐는 스택과 마찬가지로 배열을 사용하여 구현할 수 있습니다.
현재 1번 그림은 배열의 프런트부터 5개(a,b,c,d,e)의 데이터가 들어가 있는 모습입니다. 배열의 이름을 que라고 할 경우 que[0]부터 que[4]까지의 데이터가 저장됩니다.
2번 그림은 a를 디큐합니다. 디큐를 하면 프런트의 값이 +1 증가하하게 됩니다.
3번 그림도 b를 디큐하고, 프런트 값이 1 증가하였습니다. 인큐는 시간복잡도가 O(1)이지만 디큐를 하게되면 모든 요소를 하나씩 앞쪽으로 옮겨야 합니다. 이러한 문제때문에 처리의 복잡도는 O(n)이 되며 데이터를 꺼낼 때마다 이런 처리를 하게되면 효율이 떨어지는 단점이 있습니다.
이러한 문제때문에 배열 요소를 앞쪽으로 옮기지 않는 큐를 구현해 보았습니다.,
이러한 큐를 링 버퍼(ring buffer)라고 합니다. 링 버퍼는 그림처럼 배열의 처음과 끝이 연결되었다고 보는 자료구조입니다.

프런트: 맨 처음 요소의 인덱스
리어: 맨 끝 요소의 인덱스
3개의 데이터(A,B,C)가 차례대로 que[0],que[1],que[2]에 저장 됩니다. 프런트의 값은 0이고 리어 값은 3입니다. 그리고 D라는 데이터를 인큐하면 리어 값이 1만큼 증가합니다.
큐가 완전히 비어있는 상황일 경우 프런트, 리어는 0값을 가지고 있습니다. C라는 데이터를 디큐하게 되면 프런트의 값이 1증가하는것을 볼 수가 있습니다. 이렇게 큐를 구현하면 프런트와 리어 값을 업데이트하며 인큐와 디큐를 수행하기 때문에 앞에서 발생한 요소 이동 문제를 해결할 수 있습니다. 물론 처리복잡도 또한 O(1)입니다.
큐도 마찬가지로 소스코드로 구현해보았습니다.
링 버퍼 구현
public class IntQueue {
private int max; //큐의 용량
private int front; //첫벉째 요소 커서
private int rear; //마지막 요소 커서
private int num; //현재 데이터 수
private int[] que; //큐 본체
//스택과 마찬가지로 실행시 예외:큐가 비어있을때
public class EmptyIntQueueException extends RuntimeException {
public EmptyIntQueueException() {
}
}
//싱행시 예외: 큐가 가득 차있을때
public class OverflowIntQueueException extends RuntimeException {
public OverflowIntQueueException() {
}
}
//생성자
public IntQueue(int capacity) {
num = front = rear = 0;
this.max = capacity;
try {
que = new int[max]; //인자 값으로 큐 본체용 배열을 생성함
} catch (OutOfMemoryError e) { //생성할 수 없음
max = 0;
}
}
//인큐 발생시에 rear 값을 1만큼 증가시킨다.
public int enque(int x) throws OverflowIntQueueException {
if (num >= max)
throw new OverflowIntQueueException();
que[rear++] = x;
num++;
if (rear == max) //배열의 마지막 인덱스에 데이터가 존재하면 rear 값을 0으로 변경
rear = 0;
return x;
}
//디큐가 발생하면 프런트 값이 1만큼 증가한다.
public int deque() throws EmptyIntQueueException {
if (num <= 0) //큐가 비어있을때는 예외발생
throw new EmptyIntQueueException();
int x = que[front++];
num--;
if (front == max) //계속해서 디큐가 발생하여 프런트 값이 큐의 끝에 달하면 0으로 변경
front = 0;
return x;
}
//마찬가지로 큐의 프런트 부분을 읽고 출력하는 메서드
public int peek() throws EmptyIntQueueException {
if (num <= 0)
throw new EmptyIntQueueException();
return que[front];
}
//해당 데이터가 큐의 몇번째 인덱스에 들어있는지 출력하는 메서드
public int indextOf(int x) {
for (int i = 0; i < num; i++) {
int idx = (i + front) % max;
if (que[idx] == x)
return idx;
}
return -1;
}
public void clear() { //큐를 비우는 메서드
num = front = rear = 0;
}
public int capacity() { //큐의 전체크기를 반환
return max;
}
public int size() { //큐에 들어있는 데이터 개수를 반환
return num;
}
public boolean isEmpty() { //큐가 비어있는지 확인하는 메서드
return num <= 0;
}
public boolean isFull() { //큐가 가득 차있는지 확인하는 메서드
return num >= max;
}
//큐의 모든 데이터를 프런트 -> 리어 순으로 출력
public void dump() {
if (num <= 0) {
System.out.println("큐가 비어있습니다.");
}else {
for (int i = 0; i < num; i++) {
int idx = (i + front) % max;
System.out.print(que[idx] + " ");
}
System.out.println();
}
}
}링버퍼는 프런트와 리어부분만 업데이트를 해주기 때문에 인큐가 발생해도 모든 요소들을 옮기지 않아도 되고,만약 n개인 배열에 계속 데이터가 입력되면 가장 최근에 들어온 데이터 n개만 저장하고 오래된 데이터를 버리는 방식입니다. 이러한 링 버퍼를 어디서 사용할까 생각을 해보면서… 스마트 뱅킹을 사용할때 고객들이 최근 카드 결제내역 10건등을 조회하는데 링 버퍼를 이용하면 유용하지 않을까 생각을 해보았습니다.
오늘은 이렇게 자료구조를 대표하는 스택과 큐에 대해서 공부를 하면서 대학교때 대강대강 넘어가면서 보지 못했던 부분을 다시 보게되어서 보람이 있었습니다.
다음번에도 자료구조와 관련해서 다양한 알고리즘에 대해서 리뷰를 진행하겠습니다.
'알고리즘' 카테고리의 다른 글
| 해시 - 완주하지 못한 마라톤 선수 (0) | 2019.10.31 |
|---|---|
| 2018년 카카오 블라인드 공채 문제1 - 비밀지도 (0) | 2019.10.29 |
| Hackerrank- EqualizeTheArray (0) | 2019.10.28 |
| 완전탐색 - 카펫 (0) | 2019.10.25 |
| [카카오 2020 공채] 문자열 압축 (0) | 2019.10.09 |